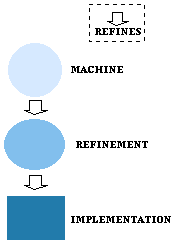
 See figure
See figureThe REFINEMENT clause is used in REFINEMENTs and IMPLEMENTATIONs to establish the refinement dependency.
An implementation is a particular form of refinement in which an implementable subset of AMN is used.
Proof obligations are associated with refinement to establish that the refining entity meets the constraints of the refined entity.
It is a matter of principle that REFINEMENTs and IMPLEMENTATIONs are only visible through the MACHINE that specifies them. MACHINEs are external interfaces, and it is only MACHINEs that can be cited in the structuring clauses: INCLUDES, USES, IMPORTS and SEES.
It is via this principle that the right separation of concerns is established for separate implementability and other information-hiding issues.
INCLUDES is transitive, i.e. included machines may include other, and so on, as illustrated in the diagram. This allows specifications to be constructed hierarchically. No cycles in the inclusion relationship are allowed.
If an abstract state can be partitioned naturally into several independent parts, then it is an advantage to use this structuring technique. A measure of this is whether the operations on the abstract state can be built from operations defined for the individual parts.
After identifying the independent parts, an included machine is written for each part. Each included machine will introduce its own state variables. To avoid name clashes in the including machine, it is best to make the name spaces of the included machines disjoint.
Several `copies' of the same machine can be included by using machine renaming, which has the effect of making the name spaces of the two copies disjoint. Note, however, that names of SETS and CONSTANTS do not participate in the renaming.
A machine is only allowed to change its local state. So if an operation of the including machine requires the state for an included machine to change in a certain way, it can only do this by invoking an operation on the included machine provided for this purpose.
The including machine state is the combined state of all its included machines. The operations which change the state are built by combining operations of the included machines.
Query operations are those that do not change the state of a machine. In an including machine, these can be written by referring directly to any of the included variables. There is therefore no point in writing query operations in machines that are only going to be included in another.
The including machine can add to the combined state by defining its own state variables, whose names must be distinct from those it is including.
While all the operations of the included machines are available to the including machine, none of these operations are part of the interface of the including machine --- unless this is explicitly specified using the PROMOTES clause.
The PROMOTES clause allows us to specify that an included operation is part of the interface of the including machine. It is simply a list of operations which we want to promote. The EXTENDS clause is used instead of INCLUDES if we want to PROMOTE all included operations.
INCLUDES and EXTENDS can only be used in MACHINEs. The PROMOTES clause can be used in an IMPLEMENTATION, but it promotes imported operations rather than included operations.
Included machines cannot be refined. The outermost including machine is the focus of refinement and implementation.
The variables of the `used' machine do not become part of the state of the using machine. They can, however, be quoted anywhere inside the `using' machine except on the left-hand side of a substitution.
You can name a parameterised machine in a USES clause, but you are not allowed to provide parameters. Nor can you reference the formal parameters of the used machine in the `using' machine.
Used machines and their `using' machines must both be included in the same `including' machine in the overall specification structure. At this level, all formal parameters of included machines are provided.
USES is not transitive, i.e. knowledge of variables from a used machine does not transfer from the using machine to any other using, including, seeing or importing machine.
The reason for this is that it is not possible to have any influence on the behaviour of non-deterministic operations from outside the machine. Through parameterisation, control can be exerted from without.
In the including machine, the proof obligations associated with included machines are assumed to be valid. Only if a new invariant is given in the including machine is there extra work to be done: the operations of the including machine have to preserve the new invariant.
The full information hiding enforced by importing allows the imported machines to be separately developed.
When a machine is imported, it is also instantiated by providing values for its formal parameters.
The `leaves' of the development tree in the B-Method are always pre-implemented library machines. Where more than one instance of a library machine is imported, the library machines have to be renamed so that the name is unique across the whole development. Thus no sharing of code can be achieved through importing alone.
Machines that are imported once somewhere in a development can be `seen' elsewhere in the development by citing the `seen' machine in a SEES clause. The code for the seen machine is linked only once in the development.
This establishes a `one writer, many readers' sharing scheme. Where the machine is imported, all operations can be invoked in the importing machine to effect state changes in the seen machine, corresponding to `write' access. Where the machine is seen, only query operations can be invoked, corresponding to `read-only' access.
A stateless machine is one which has no abstract state variables. Since they are stateless, all their operations are queries, and citing them in a SEES clause gives access to them all.
Stateless machines are typically used for sharing separately implemented system-wide types. Examples of these can be found in the System Library, such as SCALAR, BOOL, STRING. These machines contain mathematics and operations, and have an implementation.
Stateless machine may also be operation-less. These can be used for sharing a particular mathematical context between several machines. Rather than copying the same definitions into the CONSTANTS and PROPERTIES clauses of several machines, the definitions can be placed in a separate state-less (and operation-less) machine. This machine can then be cited in the SEES clause of every machine that needs the definitions.
The SEES clause can be used to share such machines at any layer of development. In fact, since SEES is not transitive, the sees machine will often have to be cited in the SEES clause of several machines down through the hierarchy.
By importing a stateless machine once and seeing it many times, only one copy of the code is present in the final system. If a machine is imported twice in a development, name clashes will arise during linking.
Operation-less machines may not need refining. Since it is just mathematics that they contain, the definitions may simply be `programmed away' in the algorithms used in the main development. However, from a book-keeping point of view, a dummy IMPLEMENTATION has to be present before linking can take place. This dummy implementation can take the following form:-
IMPLEMENTATION
My_Maths_I
REFINES
My_Maths
END
If such an implementation has not been provided, the user will be
notified if he attempts translation.
As with the USES clause above, you can name a parameterised machine in a SEES clause, but you are not allowed to provide parameters. Formal parameters are provided where the `seen' machines is imported in the development.
SEES is not transitive, i.e. knowledge of variables from a seen machine does not transfer from the seeing machine to any other using, including, seeing or importing machine.
It is this capability that makes medium to large-scale software development possible with the B-Method and B-Toolkit. Monolithic refinement of a single large specification into code is impractical. Hierarchical design allows complex systems to be specified abstractly, and implemented in detail, all within the same formal framework.
The specifications of each descending layer introduce more and more detail. The structure of the top level machine does not have to be strongly reflected in the structures of the machines in the next level down. Thus in the top level the most abstract machines can be presented in the most convenient way for specification purposes, whilst in the lower layers, they can be organised in the best way for implementation concerns, such as space and time efficiency.
There is no prescribed way of proceeding with a hierarchical design. Top-down or bottom-up designs are possible, and a mixture of the two is usually adopted.
The following is a typical approach:-
The middle layer can be used to provide an abstract instruction set specially designed to support a range of applications in the problem domain. The top layer then uses the generic functionality to implement a particular application. This approach encourages the maximum of reuse of specifications, designs and code.
A top layer can simply be a `main' program (an operation called main), which must exist before code can be executed.
One way of constructing such a top layer is by using the
Interface Generator The proofs of consistency of imported machines can be assumed
in proofs concerning the importing machine.
Not only are proofs of refinement correspondingly smaller,
but the restricted impact of changes to the development means that
fewer re-proofs have to be performed.
In this option, the Overview Tool
displays the hierarchical structure
established by the IMPORTS clauses in the development.
Design Structure and Proof
By structuring a development using IMPORTS, it is possible to
`divide and conquer' the problem of proof of refinement, as well as
that of development.
Viewing the Structure of Designs
The B-Toolkit Overview Tool can be
used to view the structure of a design, by selecting the
Design Overview
option from the Overview menu.
 © B-Core
(UK) Limited, Last updated: 22 Feb 2002
© B-Core
(UK) Limited, Last updated: 22 Feb 2002
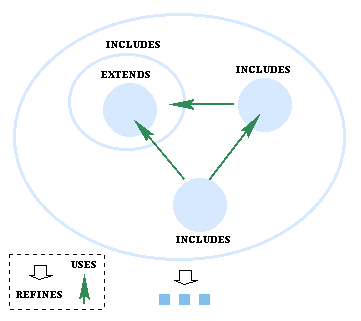 See figure
See figure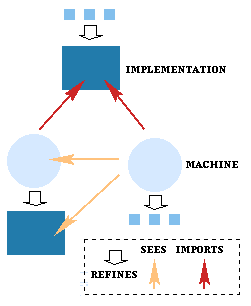 See figure
See figure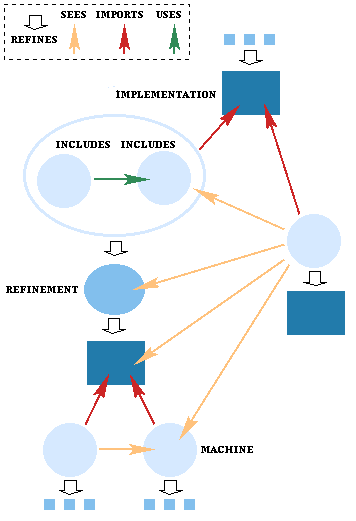 See figure
See figure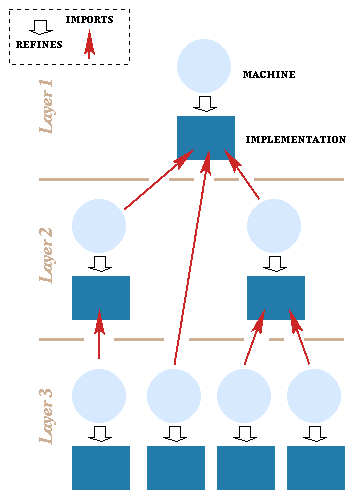 See figure
See figure